Meet Image Studio — image editing, rebuilt for speed.
Qwen Image Edit 2511 running on a single L4 GPU, with MissingLink's custom Triton kernels and optimized runtime doing the heavy lifting. Same feature set as vanilla 2511 — just efficient enough to serve batch jobs on budget hardware. Three editing modes in one browser studio: instruction-led, batch, and camera control.
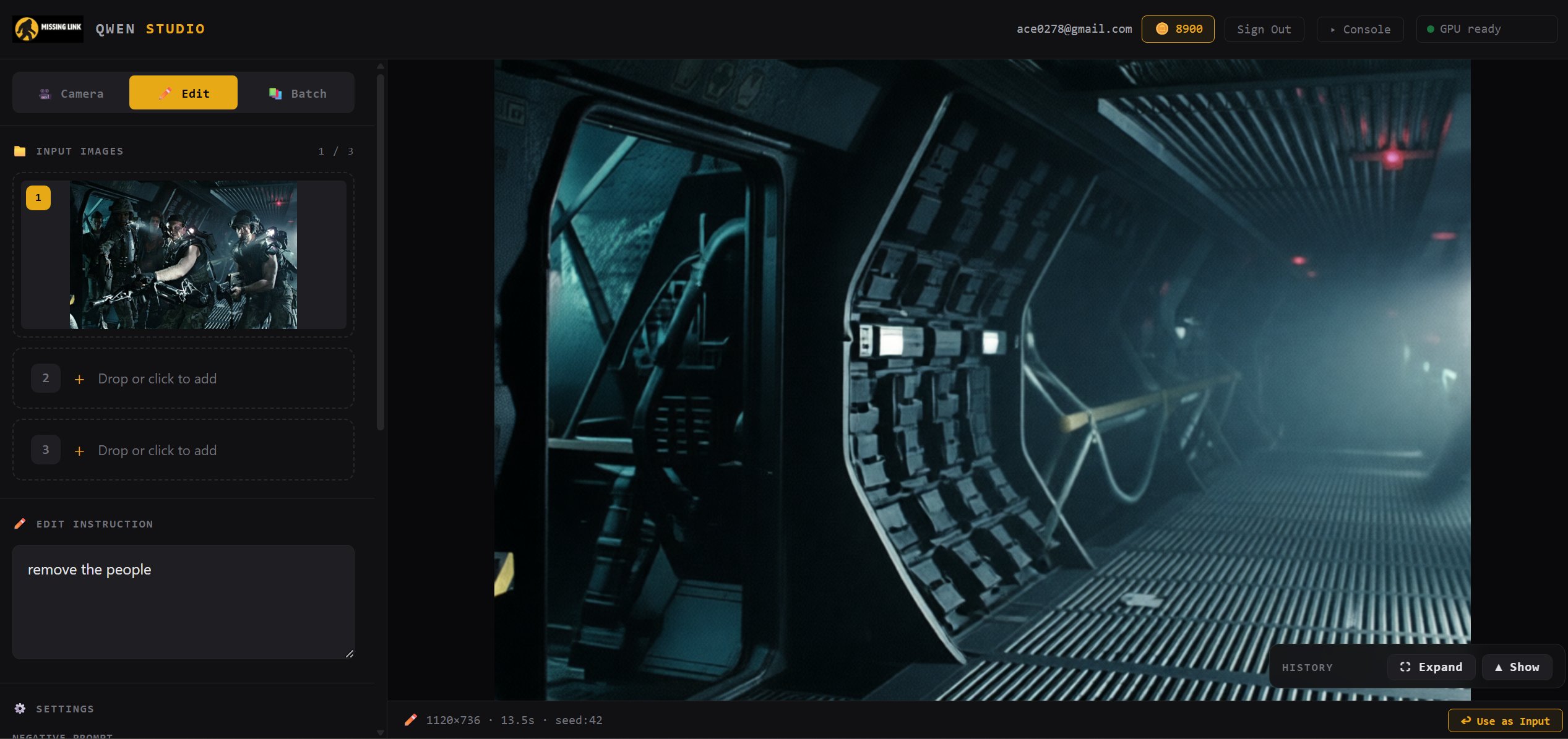
Instruction-led editing
Drop in an image, type what you want changed, and Qwen Image Edit 2511 rewrites the scene. No masks, no brushes, no complicated UI — just natural language.
- ✓ Plain-English prompts — "remove the people", "change the lighting"
- ✓ Multi-image reference for style and context transfer
- ✓ Negative prompts, seed control, and size settings exposed
- ✓ ~13 seconds per edit at 1120×736 on our optimized runtime
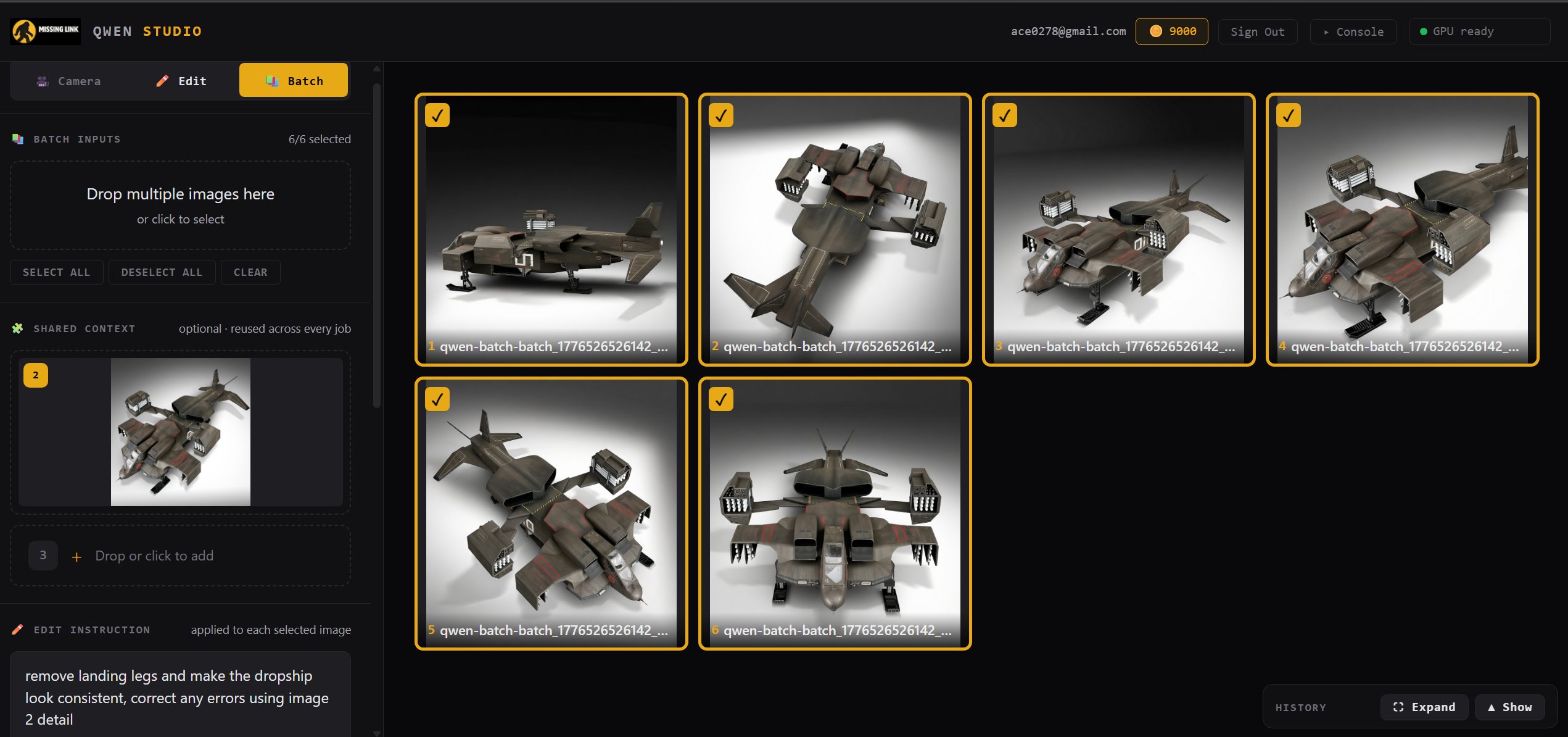
Batch editing with shared context
Queue up dozens of images, pin a shared reference for style consistency, write one instruction, and run the whole job. The shared-context approach is what makes batch viable at this price — one reference, one prompt, a whole set of edits.
- ✓ Drop multiple images, select-all / deselect-all controls
- ✓ Shared context image reused across every job for consistency
- ✓ One edit instruction applied to every selected image
- ✓ Live queue with per-image progress and history
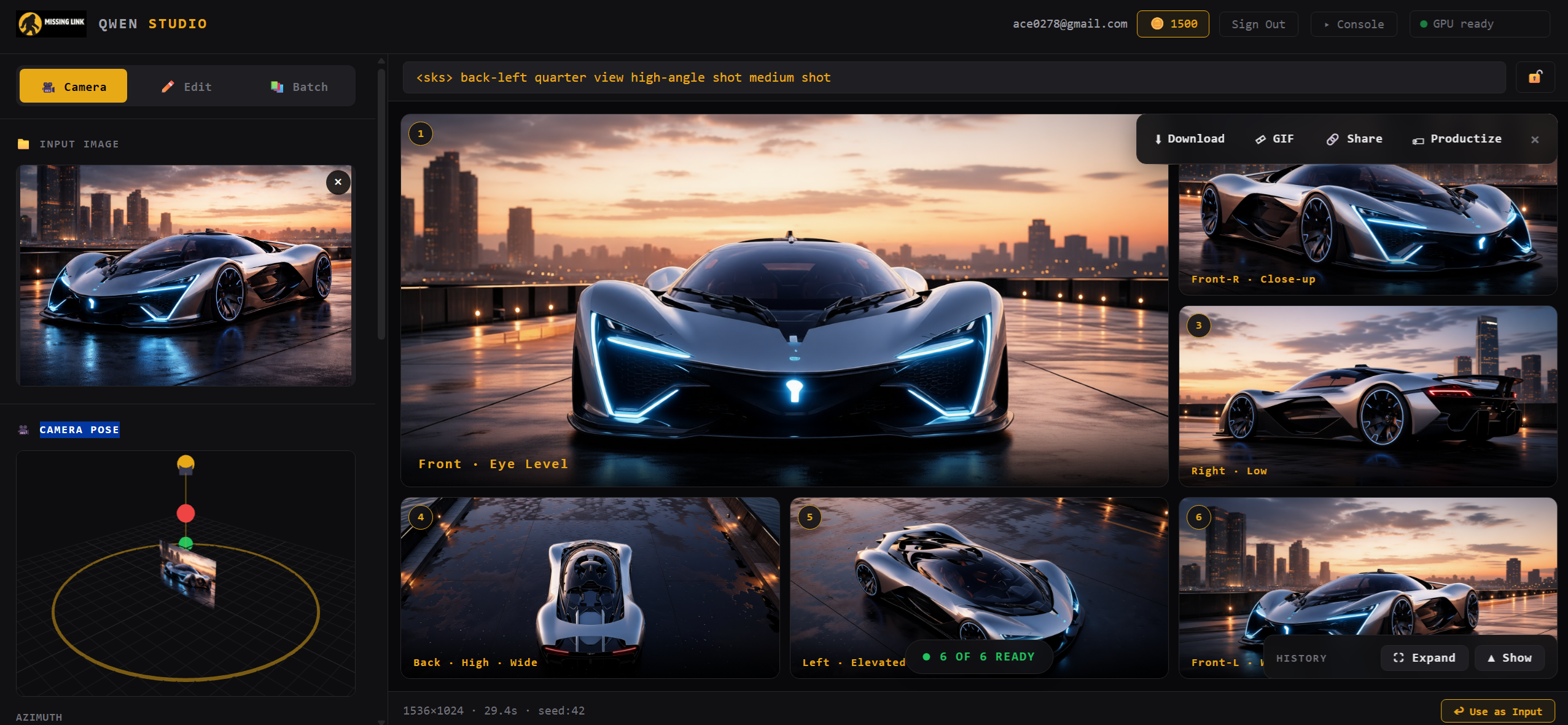
Reshoot any subject from any angle
Lock in a subject and sweep the camera around it. Front, back, side, low, high — up to 12 angles in a single click, with an orbit widget for precise control. Ideal for character reference sheets, turntables, and consistent multi-view outputs.
- ✓ Interactive azimuth / elevation orbit widget
- ✓ Preset angles: front, back, left, right, elevated, low
- ✓ Queue up to 12 renders per input image
- ✓ Subject identity preserved across every angle


